We’ve talked about arrays, linked lists, and other fundamental data structures. Now, we’re going to dive into hash maps, another essential data structure that every programmer should understand. Hash maps are incredibly efficient for storing and retrieving key-value pairs, making them essential for many programming tasks and complex algorithms. Let’s dive into what hash maps are, how they work under the hood, and their key operations and concepts!
What is a hash map?
Fundamentally, a hash map is an abstract data type (ADT) that stores key-value pairs where each key must be unique. The key can be of any data type that can be hashed (convertible via a hash function), and the value can be of any type. We will use an array to store the key-value pairs, and a hash function to convert the key into an index in the array.
A hash function is a function that takes an input and converts it into a fixed-size value. The hash function will always return the same value for the same input, and ideally it should produce unique values for different inputs as much as possible. The hash value is then used to determine the index in the array where the key-value pair will be stored.
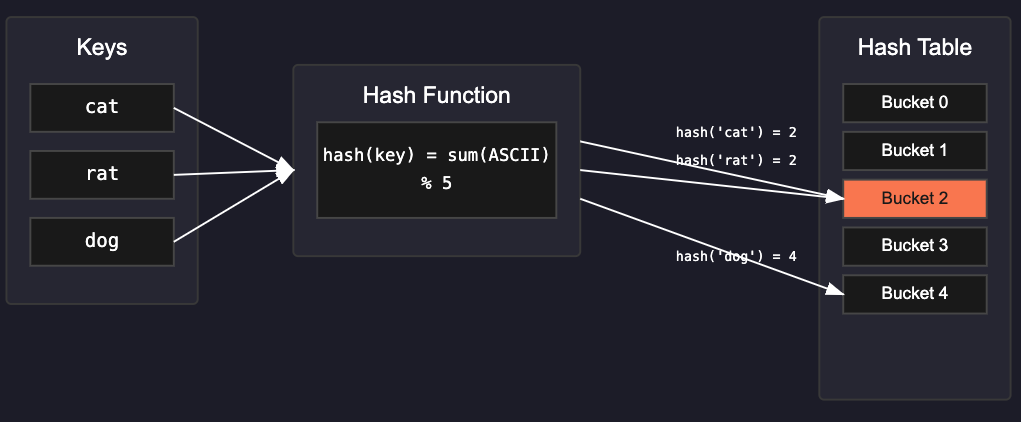
One question you might have is, we have limited number of indices in the array, but potentially infinite keys. What happens if two keys hash to the same index? Well in that case, we have a collision and there are ways to resolve the collisions. One common approach is chaining, where we use a linked list to store multiple key-value pairs at the same index and traverse the list to find the correct value for a given key.
We will use C programming language to demonstrate the concepts.
Hash Map (ADT) Properties
1. Dynamic size
Unlike arrays, hash maps can grow dynamically. When the number of elements reaches a certain number, the hash map automatically resizes itself by creating a larger internal array and rehashing all existing elements.
struct HashMap* map = createHashMap(10); // initial size of 10
// map will automatically resize when needed
2. Key-Value pairs
Hash maps store data as key-value pairs. Each key must be unique within the map, but values can be duplicated. The key is used to compute the storage location and later retrieve the associated value.
struct Pair {
char* key;
int value;
};
// Example usage
map.put("apple", 5);
map.put("banana", 8);
map.put("apple", 10); // overwrites the previous value
3. Hash function
A hash map uses a hash function to convert keys into array indices. A good hash function should:
- Be deterministic (same input always produces same output)
- Distribute values uniformly
- Be efficient to compute
unsigned int hash(char* key) {
unsigned int hash = 0;
for (int i = 0; key[i] != '\0'; i++) {
hash = 31 * hash + key[i];
}
return hash % TABLE_SIZE;
}
4. Collision handling
Since multiple keys might hash to the same index (collision), hash maps need a strategy to handle collisions. Common approaches include:
- Chaining (using linked lists at each bucket)
- Open addressing (probing for next empty slot)
struct Node {
char* key;
int value;
struct Node* next;
};
struct HashMap {
struct Node** buckets;
int size;
};
Hash Map (ADT) Operations
1. Insertion (Average O(1))
Given a key-value pair, compute the hash of the key, and store the pair in the corresponding bucket. If a collision occurs, handle it using the chosen collision resolution strategy.
void put(HashMap* map, char* key, int value) {
unsigned int index = hash(key);
Node* newNode = createNode(key, value);
if (map->buckets[index] == NULL) {
map->buckets[index] = newNode;
} else {
// Handle collision using chaining
newNode->next = map->buckets[index];
map->buckets[index] = newNode;
}
}
2. Retrieval (Average O(1))
Given a key, compute its hash and find the corresponding value in the bucket. If collision handling is used, you might need to search through the chain.
int get(HashMap* map, char* key) {
unsigned int index = hash(key);
Node* current = map->buckets[index];
while (current != NULL) {
if (strcmp(current->key, key) == 0) {
return current->value;
}
current = current->next;
}
return -1; // Key not found
}
3. Deletion (Average O(1))
Given a key, compute its hash, find and remove the corresponding key-value pair from the bucket. Handle any necessary cleanup in the collision handling structure.
void delete(HashMap* map, char* key) {
unsigned int index = hash(key);
Node* current = map->buckets[index];
Node* prev = NULL;
while (current != NULL) {
if (strcmp(current->key, key) == 0) {
if (prev == NULL) {
map->buckets[index] = current->next;
} else {
prev->next = current->next;
}
free(current);
return;
}
prev = current;
current = current->next;
}
}
4. Contains check (Average O(1))
Check if a key exists in the hash map by computing its hash and searching the appropriate bucket.
bool containsKey(HashMap* map, char* key) {
unsigned int index = hash(key);
Node* current = map->buckets[index];
while (current != NULL) {
if (strcmp(current->key, key) == 0) {
return true;
}
current = current->next;
}
return false;
}
Conclusion
In this article, we learned about hash maps, a powerful data structure that provides efficient key-value storage and retrieval. We explored their properties, including dynamic sizing and collision handling, and examined their core operations. Hash maps are essential in many programming scenarios, particularly when you need fast lookups and insertions based on unique keys.
Understanding hash maps and their implementation details is crucial for writing efficient code. While most programming languages provide built-in hash map implementations, knowing how they work under the hood helps you make better decisions about when and how to use them effectively.